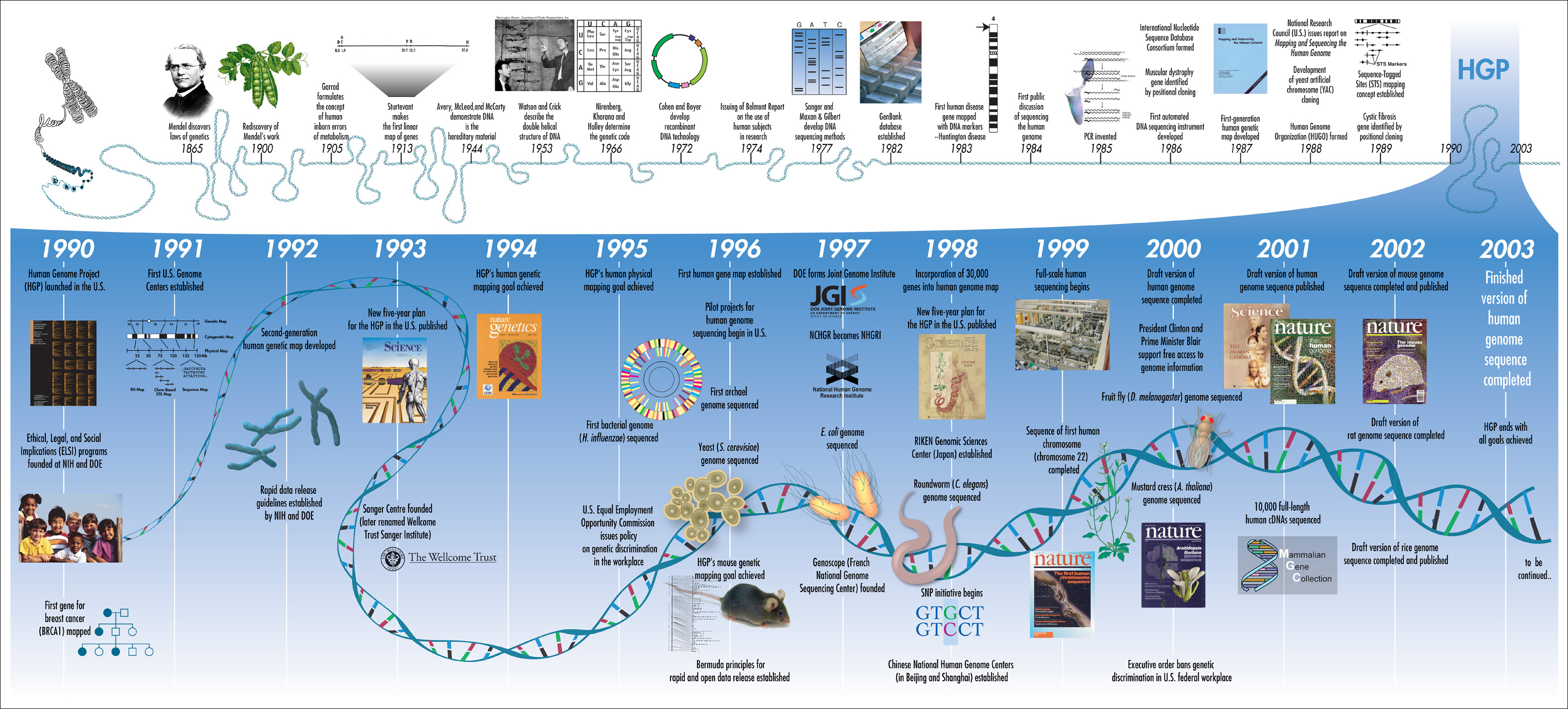
Since the rst DNA-genome, Phage -X174, was sequenced by Fred Sanger in 1977, Sanger sequencing had dominated the market approximately 25-30 years with BAC-by-BAC sequencing until Next-Gen sequencing took over the place. Since Sanger sequencing provided quite long reads (500-1000 bp), it resulted contig sizes in megabases and lead genome sequencing projects to very high quality reference genomes for human, mouse, y, rice, Arabidopsis and so on. Nevertheless it was very costly so only a few very important model species were selected for de novo sequencing.
Next-Gen sequencing supplanted Sanger sequencing with dropped cost and high-throughput. Since it is feasible to massively sequence a genome with deep coverage, literally a lot of species have been sequenced and even individuals or each cell types had been sequenced. Population genomics, comparative genomics started. Contigs, however, left exon-size. Genome finishing was abandoned. Many genome projects were ended up with draft quality genome. Quite portion of a genome are disregarded, so are regulatory elements, genes and syntheny blocks.
Now new biotechnology era begins with long read sequencing technology. Single moleculo read sequencing from PacBio (15Kbp), Moleculo long read sequencing(5Kbp), Oxford Nanopore (5-10Kbp) and 10x Genomics (50Kbp) delivere much longer reads than Next-Gen sequencing. Even longer spanning technology such as Bionano using optical mapping (100-150Kbp) and HiC/cHiCago protocal (25-100Kbp) are developed and in use. Also related algorithms such as MHAP and LACHESIS etc. are developed.
